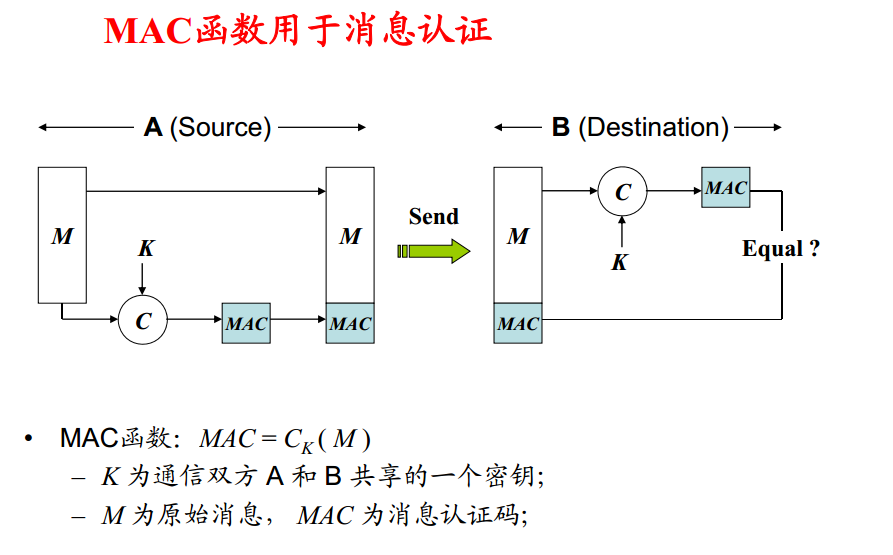
$ grep [options]
[options]主要参数:
-c:只输出匹配行的计数。
-e <范本样式>:指定字符串作为查找文件内容的范本样式。
-I:不区分大小写(只适用于单字符)。
-h:查询多文件时不显示文件名。
-l:查询多文件时只输出包含匹配字符的文件名。
-n:显示匹配行及行号。
-s:不显示不存在或无匹配文本的错误信息。
-v:显示不包含匹配文本的所有行。
-o:只输出文件中匹配到的部分。
-a 不要忽略二进制数据。
-A<显示列数> 除了显示符合范本样式的那一行之外,并显示该行之后的内容。
-b 在显示符合范本样式的那一行之外,并显示该行之前的内容。
-c 计算符合范本样式的列数。
-C<显示列数>或-<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。
-d<进行动作> 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep命令将回报信息并停止动作。
-e<范本样式> 指定字符串作为查找文件内容的范本样式。
-E 将范本样式为延伸的普通表示法来使用,意味着使用能使用扩展正则表达式。
-f<范本文件> 指定范本文件,其内容有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每一列的范本样式。
-F 将范本样式视为固定字符串的列表。
-G 将范本样式视为普通的表示法来使用。
-h 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。
-H 在显示符合范本样式的那一列之前,标示该列的文件名称。
-i 忽略字符大小写的差别。
-l 列出文件内容符合指定的范本样式的文件名称。
-L 列出文件内容不符合指定的范本样式的文件名称。
-n 在显示符合范本样式的那一列之前,标示出该列的编号。
-q 不显示任何信息。
-R/-r 此参数的效果和指定“-d recurse”参数相同。
-s 不显示错误信息。
-v 反转查找。
-w 只显示全字符合的列。
-x 只显示全列符合的列。
-y 此参数效果跟“-i”相同。
-o 只输出文件中匹配到的部分。
--exclude-dir 搜索文件内容时,排除指定的文件夹
grep正则表达式元字符集:
- ^ 锚定行的开始 如:'^grep'匹配所有以grep开头的行。
- $ 锚定行的结束 如:'grep$'匹配所有以grep结尾的行。
- . 匹配一个非换行符的字符 如:'gr.p'匹配gr后接一个任意字符,然后是p。
- * 匹配零个或多个先前字符 如:'*grep'匹配所有一个或多个空格后紧跟grep的行。 .*一起用代表任意字符。
- [] 匹配一个指定范围内的字符,如'[Gg]rep'匹配Grep和grep。
- [^] 匹配一个不在指定范围内的字符,如:'[^A-FH-Z]rep'匹配不包含A-R和T-Z的一个字母开头,紧跟rep的行。
- \(..\) 标记匹配字符,如'\(love\)',love被标记为1。
- \ 锚定单词的开始,如:'\匹配包含以grep开头的单词的行。
- \> 锚定单词的结束,如'grep\>'匹配包含以grep结尾的单词的行。
- x\{m\} 重复字符x,m次,如:'0\{5\}'匹配包含5个o的行。
- x\{m,\} 重复字符x,至少m次,如:'o\{5,\}'匹配至少有5个o的行。
- x\{m,n\}重复字符x,至少m次,不多于n次,如:'o\{5,10\}'匹配5--10个o的行。
- \w 匹配文字和数字字符,也就是[A-Za-z0-9],如:'G\w*p'匹配以G后跟零个或多个文字或数字字符,然后是p。
- \b 单词锁定符,如: '\bgrep\b'只匹配grep。
关于匹配的实例:
# 统计所有以“48”字符开头的行有多少
$ grep -c "48" test.txt
# 不区分大小写查找“May”所有的行)
$ grep -i "May" test.txt
# 显示行号;显示匹配字符“48”的行及行号,相同于 nl test.txt |grep 48)
$ grep -n "48" test.txt
# 显示输出没有字符“48”所有的行)
$ grep -v "48" test.txt
# 显示输出字符“471”所在的行)
$ grep "471" test.txt
# 显示输出以字符“48”开头,并在字符“48”后是一个tab键所在的行
$ grep "48;" test.txt
# 显示输出以字符“48”开头,第三个字符是“3”或是“4”的所有的行)
$ grep "48[34]" test.txt
# 显示输出行首不是字符“48”的行)
$ grep "^[^48]" test.txt
# 设置大小写查找:显示输出第一个字符以“M”或“m”开头,以字符“ay”结束的行)
$ grep "[Mm]ay" test.txt
# 显示输出第一个字符是“K”,第二、三、四是任意字符,第五个字符是“D”所在的行)
$ grep "K…D" test.txt
# 显示输出第一个字符的范围是“A-D”,第二个字符是“9”,第三个字符的是“D”的所有的行
$ grep "[A-Z][9]D" test.txt
# 显示第一个字符是3或5,第二三个字符是任意,以1998结尾的所有行
$ grep "[35]..1998" test.txt
# 模式出现几率查找:显示输出字符“4”至少重复出现两次的所有行
$ grep "4\{2,\}" test.txt
# 模式出现几率查找:显示输出字符“9”至少重复出现三次的所有行
$ grep "9\{3,\}" test.txt
# 模式出现几率查找:显示输出字符“9”重复出现的次数在一定范围内,重复出现2次或3次所有行
$ grep "9\{2,3\}" test.txt
# 显示输出空行的行号
$ grep -n "^$" test.txt
# 如果要查询目录列表中的目录 同:ls -d *
$ ls -l |grep "^d"
# 在一个目录中查询不包含目录的所有文件
$ ls -l |grep "^d[d]"
# 查询其他用户和用户组成员有可执行权限的目录集合
$ ls -l |grep "^d…..x..x"
# 读出logcat.log文件的内容,通过管道转发给grep作为输入内容,过滤包含"Displayed"的行,将输出内容再作为输入能过管道转发给下一个grep
$ cat logcat.log | grep -n 'Displayed' | grep ms
# 匹配testgrep文件所有wirelessqa的行
$ grep -e wirelessqa testgrep
# '^wirelessqa'匹配testgrep文件所有以wirelessqa开头的行
$ grep -e ^[wirelessqa] testgrep
# 'wirelessqa$'匹配所有以wirelessqa结尾的行
$ grep -e [wirelessqa]$ testgrep
# .*一起用代表任意字符,'.*qa'匹配任何词以qa结尾的行
$ grep -e .*qa testgrep
# '\<wire'匹配包含以wire开头的单词的行
$ grep -e '\<wire' testgrep
# 'blog\>'匹配包含以blog结尾的单词的行
$ grep -e 'blog\>' testgrep
# 匹配aaa文件中'blog.csdn.net'的行的上下5行内容
$ grep -5 -e blog.csdn.net aaa
# 显示/Users/ben目录下的文件(不含子目录)包含blog的行
$ grep blog /Users/ben
# 显示/Users/ben目录下的文件(包含子目录)包含blog的行
$ grep -r blog /Users/ben
# 结合sort和uniq一起使用可以排序并去重
# 这里使用了正则,"."是匹配一个非换行符的字符
$ cat adlog_kafka_20161204.log | grep -o 'logs.....' | sort | uniq
# 统计各行在文件中出现的次数
$ sort file.txt | uniq -c
# 在文件中找出重复的行
$ sort file.txt | uniq -d
# 搜索当前文件夹下的匹配127.0.0.1:2181的内容,排除yunyu-stt文件夹下的文件
$ grep -r "127.0.0.1:2181" . --exclude-dir="./yunyu-stt"
# 或操作
# 找出文件(filename)中包含123或者包含abc的行
$ grep -E '123|abc' filename
# 用egrep同样可以实现
$ egrep '123|abc' filename
# awk 的实现方式
$ awk '/123|abc/' filename
# 与操作
# 显示既匹配 pattern1 又匹配 pattern2 的行
$ grep pattern1 files | grep pattern2
# 其他操作
# 不区分大小写地搜索。默认情况区分大小写
$ grep -i pattern files
# 只列出匹配的文件名
$ grep -l pattern files
# 列出不匹配的文件名
$ grep -L pattern files
# 只匹配整个单词,而不是字符串的一部分(如匹配‘magic’,而不是‘magical’)
$ grep -w pattern files
# 匹配的上下文分别显示[number]行
$ grep -C number pattern files