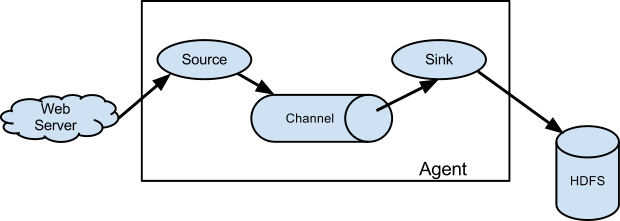
# 这里指定的agent1名称必须和flume.conf配置文件中的agent名称一致
# 这里的启动命令是./bin/flume-ng agent,开始监听41414端口
$ ./bin/flume-ng agent --conf ./conf/ -f conf/flume.conf -Dflume.root.logger=DEBUG,console -n agent1
+ exec /Library/Java/JavaVirtualMachines/jdk1.7.0_79.jdk/Contents/Home/bin/java -Xmx20m -Dflume.root.logger=DEBUG,console -cp '/Users/yunyu/dev/flume-1.6.0/conf:/Users/yunyu/dev/flume-1.6.0/lib/*' -Djava.library.path= org.apache.flume.node.Application -f conf/flume.conf -n agent1
2016-08-24 10:15:05,547 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.node.PollingPropertiesFileConfigurationProvider.start(PollingPropertiesFileConfigurationProvider.java:61)] Configuration provider starting
2016-08-24 10:15:05,551 (lifecycleSupervisor-1-0) [DEBUG - org.apache.flume.node.PollingPropertiesFileConfigurationProvider.start(PollingPropertiesFileConfigurationProvider.java:78)] Configuration provider started
2016-08-24 10:15:05,553 (conf-file-poller-0) [DEBUG - org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:126)] Checking file:conf/flume.conf for changes
2016-08-24 10:15:05,555 (conf-file-poller-0) [INFO - org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:133)] Reloading configuration file:conf/flume.conf
2016-08-24 10:15:05,559 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty(FlumeConfiguration.java:1017)] Processing:log-sink1
2016-08-24 10:15:05,559 (conf-file-poller-0) [DEBUG - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty(FlumeConfiguration.java:1021)] Created context for log-sink1: type
2016-08-24 10:15:05,560 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty(FlumeConfiguration.java:1017)] Processing:log-sink1
2016-08-24 10:15:05,560 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty(FlumeConfiguration.java:931)] Added sinks: log-sink1 Agent: agent1
2016-08-24 10:15:05,563 (conf-file-poller-0) [DEBUG - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.isValid(FlumeConfiguration.java:314)] Starting validation of configuration for agent: agent1, initial-configuration: AgentConfiguration[agent1]
SOURCES: {avro-source1={ parameters:{port=41414, channels=ch1, type=avro, bind=10.10.1.23} }}
CHANNELS: {ch1={ parameters:{type=memory} }}
SINKS: {log-sink1={ parameters:{type=logger, channel=ch1} }}
2016-08-24 10:15:05,566 (conf-file-poller-0) [DEBUG - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.validateChannels(FlumeConfiguration.java:469)] Created channel ch1
2016-08-24 10:15:05,573 (conf-file-poller-0) [DEBUG - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.validateSinks(FlumeConfiguration.java:675)] Creating sink: log-sink1 using LOGGER
2016-08-24 10:15:05,574 (conf-file-poller-0) [DEBUG - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.isValid(FlumeConfiguration.java:372)] Post validation configuration for agent1
AgentConfiguration created without Configuration stubs for which only basic syntactical validation was performed[agent1]
SOURCES: {avro-source1={ parameters:{port=41414, channels=ch1, type=avro, bind=10.10.1.23} }}
CHANNELS: {ch1={ parameters:{type=memory} }}
AgentConfiguration created with Configuration stubs for which full validation was performed[agent1]
SINKS: {log-sink1=ComponentConfiguration[log-sink1]
CONFIG:
CHANNEL:ch1
}
2016-08-24 10:15:05,574 (conf-file-poller-0) [DEBUG - org.apache.flume.conf.FlumeConfiguration.validateConfiguration(FlumeConfiguration.java:136)] Channels:ch1
2016-08-24 10:15:05,575 (conf-file-poller-0) [DEBUG - org.apache.flume.conf.FlumeConfiguration.validateConfiguration(FlumeConfiguration.java:137)] Sinks log-sink1
2016-08-24 10:15:05,575 (conf-file-poller-0) [DEBUG - org.apache.flume.conf.FlumeConfiguration.validateConfiguration(FlumeConfiguration.java:138)] Sources avro-source1
2016-08-24 10:15:05,575 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration.validateConfiguration(FlumeConfiguration.java:141)] Post-validation flume configuration contains configuration for agents: [agent1]
2016-08-24 10:15:05,577 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.loadChannels(AbstractConfigurationProvider.java:145)] Creating channels
2016-08-24 10:15:05,584 (conf-file-poller-0) [INFO - org.apache.flume.channel.DefaultChannelFactory.create(DefaultChannelFactory.java:42)] Creating instance of channel ch1 type memory
2016-08-24 10:15:05,591 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.loadChannels(AbstractConfigurationProvider.java:200)] Created channel ch1
2016-08-24 10:15:05,592 (conf-file-poller-0) [INFO - org.apache.flume.source.DefaultSourceFactory.create(DefaultSourceFactory.java:41)] Creating instance of source avro-source1, type avro
2016-08-24 10:15:05,610 (conf-file-poller-0) [INFO - org.apache.flume.sink.DefaultSinkFactory.create(DefaultSinkFactory.java:42)] Creating instance of sink: log-sink1, type: logger
2016-08-24 10:15:05,614 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.getConfiguration(AbstractConfigurationProvider.java:114)] Channel ch1 connected to [avro-source1, log-sink1]
2016-08-24 10:15:05,623 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:138)] Starting new configuration:{ sourceRunners:{avro-source1=EventDrivenSourceRunner: { source:Avro source avro-source1: { bindAddress: 10.10.1.23, port: 41414 } }} sinkRunners:{log-sink1=SinkRunner: { policy:org.apache.flume.sink.DefaultSinkProcessor@8ae0e27 counterGroup:{ name:null counters:{} } }} channels:{ch1=org.apache.flume.channel.MemoryChannel{name: ch1}} }
2016-08-24 10:15:05,632 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:145)] Starting Channel ch1
2016-08-24 10:15:05,700 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:120)] Monitored counter group for type: CHANNEL, name: ch1: Successfully registered new MBean.
2016-08-24 10:15:05,701 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:96)] Component type: CHANNEL, name: ch1 started
2016-08-24 10:15:05,701 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:173)] Starting Sink log-sink1
2016-08-24 10:15:05,702 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:184)] Starting Source avro-source1
2016-08-24 10:15:05,702 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.AvroSource.start(AvroSource.java:228)] Starting Avro source avro-source1: { bindAddress: 10.10.1.23, port: 41414 }...
2016-08-24 10:15:05,702 (SinkRunner-PollingRunner-DefaultSinkProcessor) [DEBUG - org.apache.flume.SinkRunner$PollingRunner.run(SinkRunner.java:143)] Polling sink runner starting
2016-08-24 10:15:06,036 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:120)] Monitored counter group for type: SOURCE, name: avro-source1: Successfully registered new MBean.
2016-08-24 10:15:06,036 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:96)] Component type: SOURCE, name: avro-source1 started
2016-08-24 10:15:06,036 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.AvroSource.start(AvroSource.java:253)] Avro source avro-source1 started.